Define File/Field map from Source File
This page describes how to map incoming data to Appx files/Fields using an existing XML file as a guide. _Overview:
In order to use this option, you need a sample of the import file to work with. You can upload the file and then use it as a guide to create your File/Field Mapping. Once the mapping is complete, you can optionally import the data.Usage
When you run 'Define File/Field Map from Source File', you will see the following display: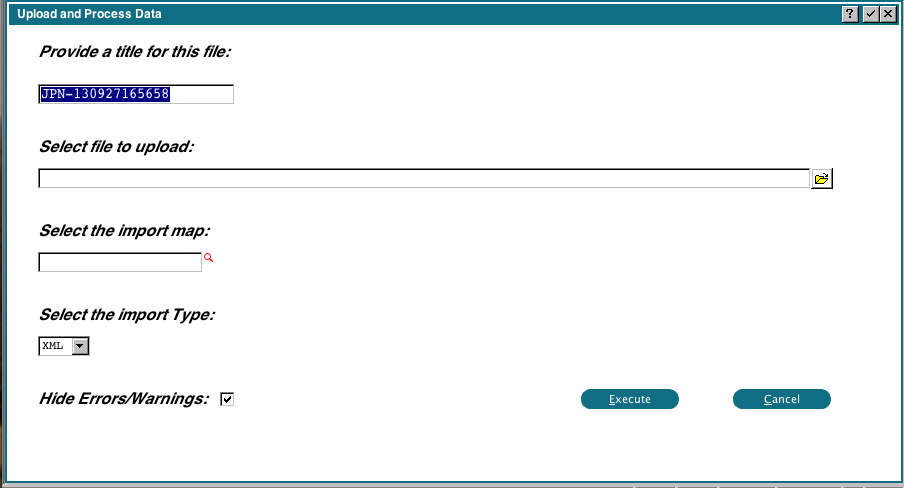 The title will default to your user initials, plus the current date/time. You can change this if you wish. You can drag and drop an XML file, or use the file chooser. If you are going to base your new mapping on an existing mapping, you can enter the import map name. Currently 0DX only supports XML, you cannot change that. The 'Hide Errors/Warnings' flag normally suppresses any problems with the source file. If you are having problems importing a file, you can uncheck this flag to see if there are any formatting problems with the incoming data.
Once you click 'Execute' the tags and data will be extracted from the XML file, and you will be able to refer to them as you create your mapping. When this is complete, you will see the following display:
The title will default to your user initials, plus the current date/time. You can change this if you wish. You can drag and drop an XML file, or use the file chooser. If you are going to base your new mapping on an existing mapping, you can enter the import map name. Currently 0DX only supports XML, you cannot change that. The 'Hide Errors/Warnings' flag normally suppresses any problems with the source file. If you are having problems importing a file, you can uncheck this flag to see if there are any formatting problems with the incoming data.
Once you click 'Execute' the tags and data will be extracted from the XML file, and you will be able to refer to them as you create your mapping. When this is complete, you will see the following display:
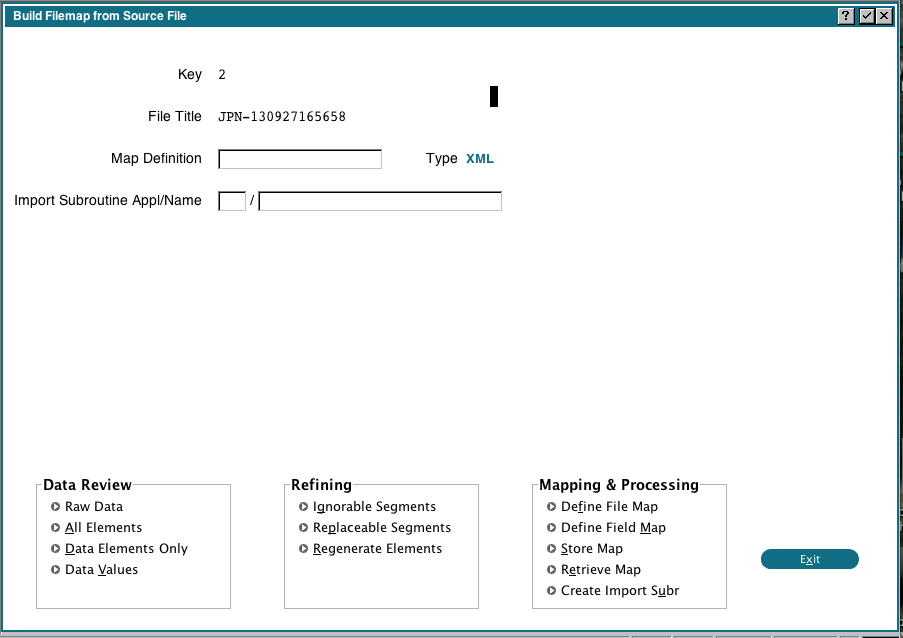 If you entered a Map name in the first step, that mapping will be loaded for you and the name will be shown here. At this point, all the elements and data have been extracted and are stored in some internal files in the 0DX application. We can use those to help us map the files and fields.
If you entered a Map name in the first step, that mapping will be loaded for you and the name will be shown here. At this point, all the elements and data have been extracted and are stored in some internal files in the 0DX application. We can use those to help us map the files and fields.
Data Review
The Data Review options allow us to examine the extracted data.Raw Data
The 'Raw Data' option displays all the extracted identifiers and the associated data: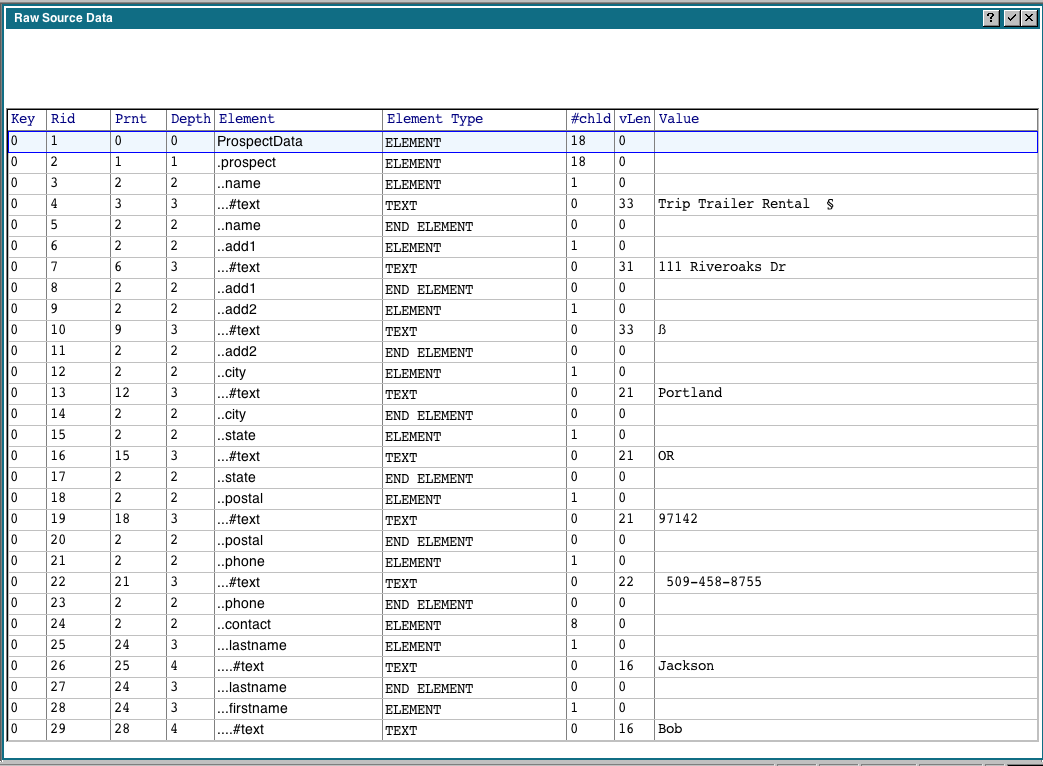 The columns have the following meanings:
The columns have the following meanings:
- Key is a sequential number assigned to each file you process. You can have multiple files processed and awaiting import at the same time.
- RID is a 'Row Id' assigned to each extracted identifier. It does not refer to a line number in the source file
- Prnt is the 'Parent' row id for that row. In the example above. RID 1 is the ProspectData element, which is the top level element in our XML file. RID 2 is an element under ProspectData, so it's Parent is RID 1
- Depth refers to the nesting of the current element.
- Element is a abbreviated identifier, where the leading portions are replaced by a period. For example, '..name' would expand to <ProspectData><Prospect><name>
- Element type refers to the different types that are extracted. ELEMENT indicates the beginning of a new element. TEXT and ATTR will contain the data and attributes, and END ELEMENT indicates the end of the element.
- #chld refers to the number of children for the current element. For example. '.prospect' has 18 children because there were 9 <prospect> and 9 </prospect> tags in our source file.
- vLen refers to the length of the longest data string
- Value shows the actual data for the selected element.
All Elements/Data Elements
The 'All Elements' and 'Data Elements only' display the same information, the only difference is the 'Data Elements only' will only show you the elements that contain data: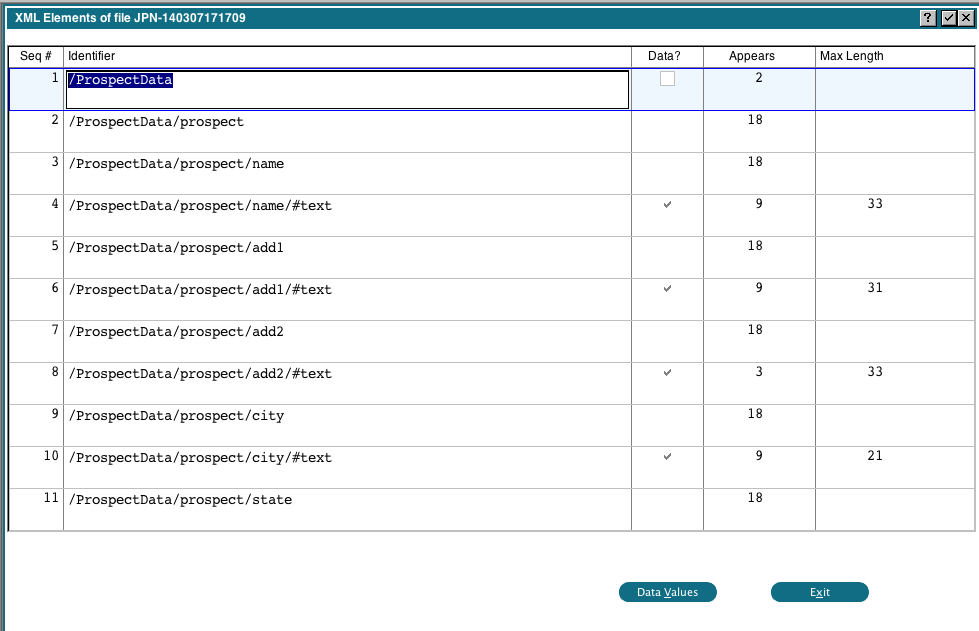 The columns have the following meanings:
The columns have the following meanings:
- Seq # is a sequential number assigned to each row. This does not refer to a line number in the source file
- Identifier is the extracted identifier
- Data is a flag that indicates whether this element contains data or not.
- Appears is a count of the number of times this element appears in the source file.
- Max Length is the maximum length of the data for this element.
Data Values
You can click the 'Data Values' button for any selected row, and you will get a display of all the actual data values for each occurence of the element: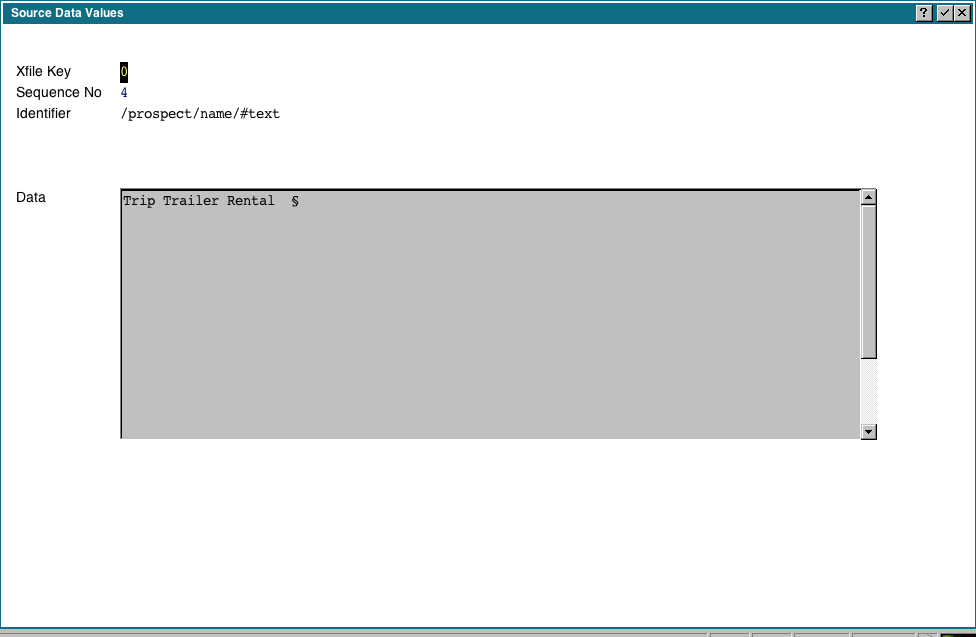 The 'Data Values' option shows us the same information as above, but not constrained to any element, ie, we can scroll thru all the extracted data.
The 'Data Values' option shows us the same information as above, but not constrained to any element, ie, we can scroll thru all the extracted data.
Refining
The 'Refining' section allows us to fine tune the extraction of identifiers from the XML file.Ignorable Segments
In the 'Ignorable Segments' popup we can specify segments that are to be ignored (removed) when extracting the identifiers. For example, if 'ProspectData' was the top level identifier and is prefixed on all identifiers, we can remove it by entering 'ProspectData' as a segment to be ignored.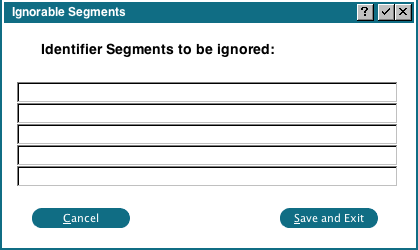
Replaceable Segments
'Replaceable Segments' are used for a very particular situation. Consider the following XML fragment:<j2:feature name="SourceName">
<j2:value>136</j2:value>
</j2:feature>
<j2:feature name="FileSystemProperties">
<j2:features>
<j2:feature name="Path">
<j2:value>/usr/local/appx/archive/110928/136</j2:value>
</j2:feature>
<j2:feature name="LastModified">
<j2:value>2011-09-28T20:19:52-04:00</j2:value>
</j2:feature>
</j2:features>
Notice that the Segments all have the same name (j2:feature), and the identifier is really encoded in the attribute (name="..."). In this case, we can use the Replaceable Segments to move the attribute to the segment, which will allow us to map the segment to an Appx field:
 Now our segment names will become "SourceName", "FileSystemProperties", "Path", "LastModified" instead of "j2:feature"
Now our segment names will become "SourceName", "FileSystemProperties", "Path", "LastModified" instead of "j2:feature"
Regenerate Elements
Whenever you change the Ignorable or Replaceable segments, you must run 'Regenerate Elements' to reprocess the XML file using your new rules.Mapping and Processing
This is where we can enter or modify the mapping rules. A 'File Map' indicates when a new record should be written to the Appx file, and a 'Field Map' indicates how the incoming data should be moved to an Appx field.Define File Map
When you run 'Define File Map' you will see the following display: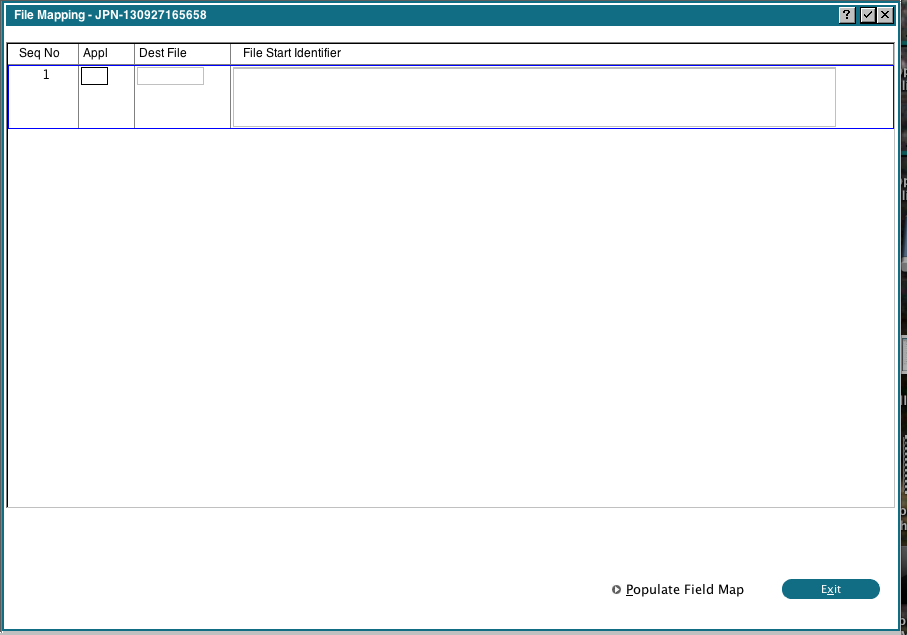 If you provided a map when you loaded the source file, then any existing File Mappings will be shown. The columns have the following meaning:
If you provided a map when you loaded the source file, then any existing File Mappings will be shown. The columns have the following meaning:
- Appl is the Application Id of file to be written
- Dest File is the name of the Appx file to be written
- File Start Identifier is the XML identifier that should trigger writing a new record. You can Scan the identifiers in the current source file.
Define Field Map
When you run 'Define Field Map' you will see the following display: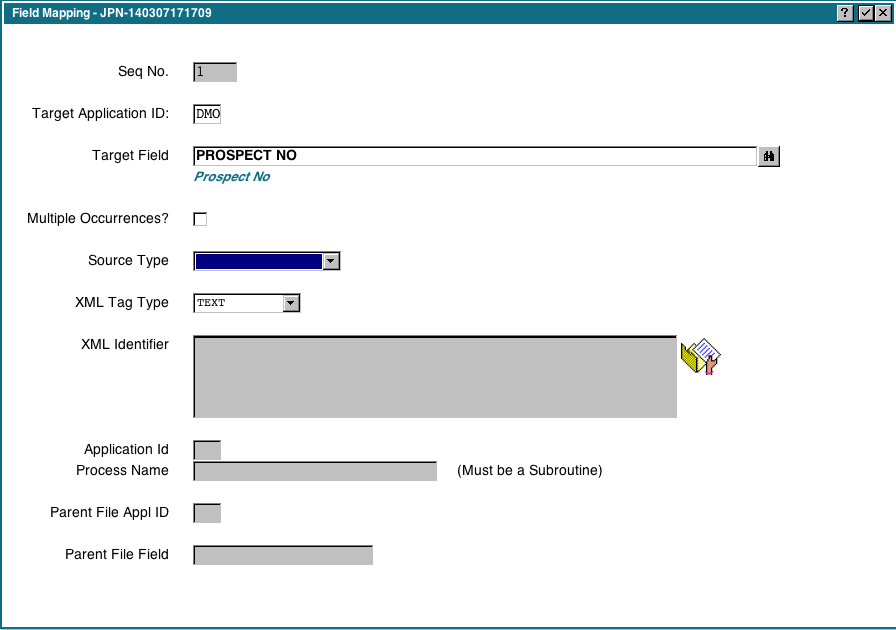 This is where we define how each Appx field should be populated. If you ran the 'Populate Field Map' option in the previous step, then this display will be populated with all the fields in the selected file(s). If you did not do that, you have to manually add each field we are importing.
For each field choose an appropriate 'Source Type'. if you leave the 'Source Type' blank they will be assigned the default values as per the Data Dictionary.
The valid source types are:
This is where we define how each Appx field should be populated. If you ran the 'Populate Field Map' option in the previous step, then this display will be populated with all the fields in the selected file(s). If you did not do that, you have to manually add each field we are importing.
For each field choose an appropriate 'Source Type'. if you leave the 'Source Type' blank they will be assigned the default values as per the Data Dictionary.
The valid source types are:
- XML Data Field. When you choose this type, the XML Identifier, Application Id and Proces Name fields will become available for input. You can Scan on the XML Identifier field to choose an identifier that exists in the current XML file. The Application Id and Process Name allow us to specify a subroutine that you want to run when this field is imported (optional). The subroutine will be invoked DETACHED and will be passed 2 fields. You should RECEIVE 2 fields, the first field is the data extracted from the XML file and the second field is the XML identifier. You can change the first field, and the resulting data will be written to the Appx file.
- Parent APPX File. You use this when you want the Appx field to be filled in from another (Parent) Appx File. For example, when importing the Contacts, we want the CONTACT PROSPECT NO field to be filled in from PROSPECT NO. When we choose this type, the Application Id, Parent File Id and Parent File Field fields will become available for input.
- Sequence Number. Use this to automatically assign a sequential sequence number to the Appx field. Note that the sequence number starts at zero every time you run the import step, so normally you would not use this to generate unique keys in an existing Appx file that uses a sequence number key.
- Date/Time Stamp. The current date/time will be set in the field.
Store Map
This option allows you to save the current mapping. If you enter the name of an existing mapping, it will be overwritten with the new mapping.
If you enter the name of an existing mapping, it will be overwritten with the new mapping.
Retrieve Map
This option allows you to load an existing mapping. After loading it, you can refine it using the 'Define File Map' and 'Define Field Map' options, then save it under a new name or replace the original, using the 'Store Map' option.
Create Import Subr
This option will create a subroutine that does the work of importing the XML data into our Appx files: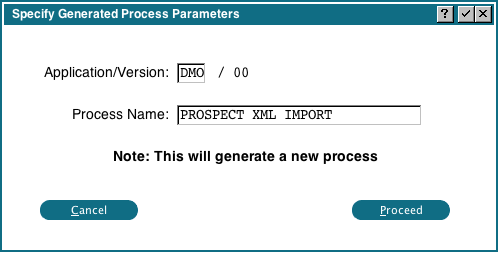 Fill in any Application and Process Name you want. When you click 'Proceed', the subroutine will be written and compiled. If any errors occur during the compile, you can view the subroutine in Application Design. You can also further customize the subroutine, however, you will lose those changes if you 'Create Import Subr' again.
Fill in any Application and Process Name you want. When you click 'Proceed', the subroutine will be written and compiled. If any errors occur during the compile, you can view the subroutine in Application Design. You can also further customize the subroutine, however, you will lose those changes if you 'Create Import Subr' again.
Comments:
Read what other users have said about this page or add your own comments.-- JeanNeron - 2013-10-02

Ideas, requests, problems regarding TWiki? Send feedback