Difference: Appx610Features (47 vs. 48)
Revision 482022-04-29 - BrianRyan
| Line: 1 to 1 | |||||||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
APPX 6.1.0 Features | |||||||||||||||||||||||||||
| Changed: | |||||||||||||||||||||||||||
| < < | _This page provides an overview of the new features in APPX 6.1.x | ||||||||||||||||||||||||||
| > > | This page provides an overview of the new features in APPX 6.1.x | ||||||||||||||||||||||||||
OverviewThe most significant change in this is release is support for a Unicode data type. From Wikipedia: "Unicode is a computing industry standard for the consistent encoding, representation, and handling of text expressed in most of the world's writing systems. The latest version contains a repertoire of 136,755 characters covering 139 modern and historic scripts, as well as multiple symbol sets. The Unicode Standard is maintained in conjunction with ISO/IEC 10646, and both are code-for-code identical." The addition of Unicode will allow you to develop APPX applications to run in any language. 'UNICODE' is a new storage attribute for Alpha and Text fields. You can change this attribute, restructure the file, and APPX will accept Unicode data in that field. Although you may see some references to a NATIONAL encoding type, it is not implemented in this release. When storing the data in APPX/IO, APPX uses the UTF-32 format, which requires 4 bytes for each character. When printing Unicode data in a non PDF report or reading/writing a stream file, APPX uses UTF-8. The UTF-8 standard uses 1 to 4 bytes per character. It was designed for backward compatibility with ASCII. The first 128 characters of Unicode, which correspond one-to-one with ASCII, are encoded using a single octet with the same binary value as ASCII, so that valid ASCII text is valid UTF-8-encoded Unicode as well. Printing Unicode characters in a PDF document is handled by the inclusion of the DejaVu Font library. This is an open source font collection designed for greater coverage of Unicode, as well as providing more styles. Since there are over 1 million possible Unicode characters, not every font family can print all the characters. You may need to source a different font library if your target language is not fully supported in DejaVu. APPX provides a way for you to override the default fonts. The fonts will be embedded in the PDF document and will display regardless of which fonts are installed on the user's desktop. Transcoding is the act of converting to or from Unicode. APPX handles this for you automatically. However, if you move a field containing Unicode data to a non Unicode field and the Unicode data cannot be transcoded to the target encoding a runtime error will occur. This is similar to an overflow condition with a numeric field. We do not want to simply continue, as you have lost data in this case. There are also APIs for transcoding that give you more control. Various fields in APPX System Administration and Application Design have been converted to Unicode. As a result of this, System Administration, Application Design and all Structure files are incompatible between Release 6 and any earlier release. A migration tool is provided to move the System Administration and Application Design files to Release 6.x. See Upgrading an Existing installation for the details. Unicode is not accepted everywhere in the System Administration or Application Design files. Only those fields that are 'user-facing' have been changed. For example, Printer Descriptions, Form Descriptions, Field Descriptions, Field Column Headings are all Unicode. Fields the end user does not see, such as Process Names, File names, etc., are not Unicode. To check if a field accepts Unicode or not, just press Help (F1). The help text will tell you if it is a Unicode field. This release has increased memory requirements, and performance in some areas is slow. We are aware of these issues, and they will be addressed in the next patch release.Application Design ConsiderationsAll --- TEMP fields are now Unicode. This may have an impact if you are PASSing a TEMP field to an internal or external routine or program. If it isn't expecting Unicode, that may be a problem. A number of --- WORK RAW xx fields have been added - you can use these in place of --- TEMP fields if you need a non Unicode field. The new API's have been enhanced to work with Unicode fields, but the older ones have not. You may need to update your applications to use the newer APIs. Unicode is not accepted in ILF statements or Enduser/Designer Selections in a Query. Unicode is accepted in a Query at runtime. If you must refer to a Unicode character in ILF, you can use the \uxxxx syntax. For example, to use the ❤ symbol you could use: | |||||||||||||||||||||||||||
| Added: | |||||||||||||||||||||||||||
| > > | |||||||||||||||||||||||||||
SET --- TEMP 1 = \u2764where 2764 is the code point for the ❤ symbol. Since Unicode is not allowed in ILF, the 'Delimited Exporter' in the Data Dictionary toolbox will substitute a ? for Unicode characters if generating a row of field names. If a Group field contains a Unicode field, you cannot SET that group to or from an Alpha field. The process will give an 'Invalid Storage Type' compile error. Similarly, Unicode fields cannot be set into a Group field. This may have an impact on your applications if you are using --- TEMP fields to move data to/from a group, since all --- TEMP fields are Unicode. You can use one of the new WORK RAW fields instead. If a group field contains a Unicode field, it can only be moved to/from another group field. There are many new fields on the GUI Attributes screens for Items on an Image. Because of this, we recommend using at least 27 rows in your Desktop Client settings. There are additional considerations discussed in more detail at the end of the Upgrade instructions. Changes in Release 6.1.0Here is a list of the changes in Release 6.1.0:Record Length and Field Length Limits IncreasedThe maximum size of an Alpha/Text field is now 1M (1,048,576) characters. The maximum record length for an APPX/IO Type 9 (Large File) increased to 4,194,560 bytes. This is enough to store a maximum field size (1M Unicode characters) + maximum key size (255 bytes) + 1 alignment byte. APPX/IO Type 1 file record length limit remains at 32K. Oracle or MS SQL Server don't have record length limit.UnicodeYou can now specify a 'Unicode' encoding type for Alpha and Text fields. This is entered in the Additional Attributes dialog box: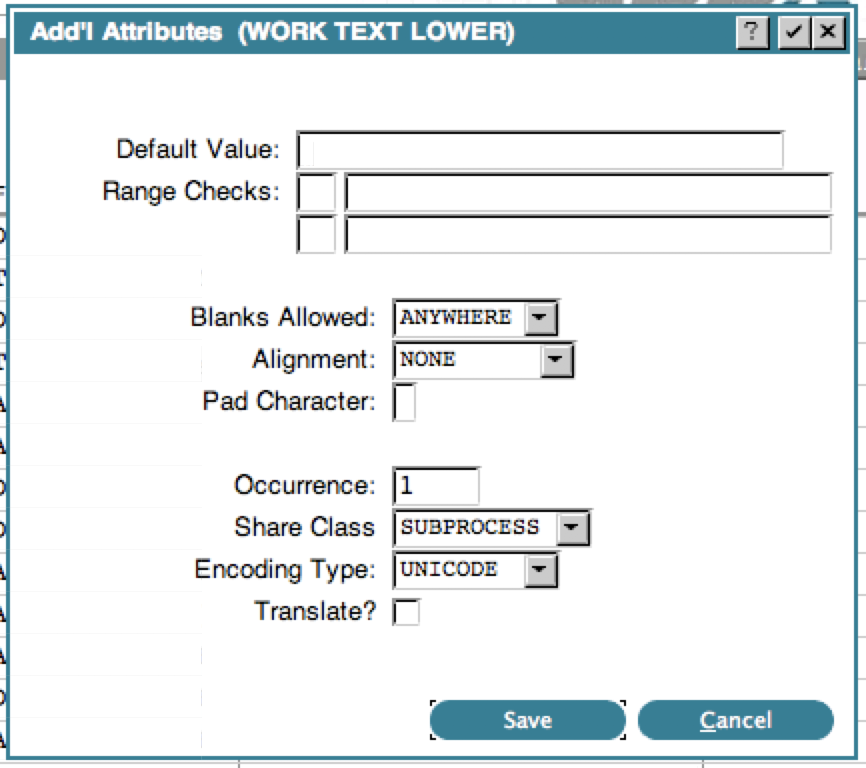 The default encoding type is RAW, which corresponds to US ASCII (ISO-8859-15). If you are not using ISO-8859-15 as your default encoding, then set the APPX_RAW_ENCODING environment variable to tell APPX which encoding you are using.
Unicode fields must be aligned on a 4 byte boundary. When the file is processed, APPX will check this and warn you if you need to add alignment bytes. Simply add an alpha field of the designated length in front of your Unicode field. If you have more than one Unicode field in your file, you may have to add multiple alignment bytes.
If the new record length is > 32K, you will get a warning from the Data Dictionary compiler. If you are going to store this file in Oracle or SQL Server, you can ignore this. If you are using APPX/IO Type 9 file, the new record length limit is 4,194,560. However, the 32k limit still applies to APPX/IO Type 1 files.
In order to display or print Unicode data, the field must have a GUI Attribute of either a LABEL (non modifiable field on an Input or normal field on an Output) or RAW TEXT. The default font for a LABEL is Arial, which may be noticeable if the other fields on the image are not. You can override the default font to COURIER to use the same font as fields without a GUI attribute.
You also need to consider how this field is used. If it is moved to a non Unicode field (via SET or RECEIVE) that will cause a runtime error to occur if the source field contains Unicode characters that cannot be transcoded. To prevent this, all target fields must also be Unicode and any fields they are moved to, and so on.
APPX ships with the DejaVu fonts for PDF printing. You can install a different set of fonts if required, and then use the following environment variable to override the defaults:
APPX_PDF_FONT_PATH=<location of font files, default $APPXPATH/fonts/>
APPX_PDF_FONT_MONO=DejaVuSansMono
The default encoding type is RAW, which corresponds to US ASCII (ISO-8859-15). If you are not using ISO-8859-15 as your default encoding, then set the APPX_RAW_ENCODING environment variable to tell APPX which encoding you are using.
Unicode fields must be aligned on a 4 byte boundary. When the file is processed, APPX will check this and warn you if you need to add alignment bytes. Simply add an alpha field of the designated length in front of your Unicode field. If you have more than one Unicode field in your file, you may have to add multiple alignment bytes.
If the new record length is > 32K, you will get a warning from the Data Dictionary compiler. If you are going to store this file in Oracle or SQL Server, you can ignore this. If you are using APPX/IO Type 9 file, the new record length limit is 4,194,560. However, the 32k limit still applies to APPX/IO Type 1 files.
In order to display or print Unicode data, the field must have a GUI Attribute of either a LABEL (non modifiable field on an Input or normal field on an Output) or RAW TEXT. The default font for a LABEL is Arial, which may be noticeable if the other fields on the image are not. You can override the default font to COURIER to use the same font as fields without a GUI attribute.
You also need to consider how this field is used. If it is moved to a non Unicode field (via SET or RECEIVE) that will cause a runtime error to occur if the source field contains Unicode characters that cannot be transcoded. To prevent this, all target fields must also be Unicode and any fields they are moved to, and so on.
APPX ships with the DejaVu fonts for PDF printing. You can install a different set of fonts if required, and then use the following environment variable to override the defaults:
APPX_PDF_FONT_PATH=<location of font files, default $APPXPATH/fonts/>
APPX_PDF_FONT_MONO=DejaVuSansMonoAPPX_PDF_FONT_MONO_BOLD=DejaVuSansMono-Bold APPX_PDF_FONT_MONO_ITALIC=DejaVuSansMono-Oblique APPX_PDF_FONT_MONO_BOLD_ITALIC=DejaVuSansMono-BoldOblique APPX_PDF_FONT_SANS=DejaVuSansCondensed APPX_PDF_FONT_SANS_BOLD=DejaVuSansCondensed-Bold APPX_PDF_FONT_SANS_ITALIC=DejaVuSansCondensed-Oblique APPX_PDF_FONT_SANS_BOLD_ITALIC=DejaVuSansCondensed-BoldOblique APPX_PDF_FONT_SERIF=DejaVuSerifCondensed APPX_PDF_FONT_SERIF_BOLD=DejaVuSerifCondensed-Bold APPX_PDF_FONT_SERIF_ITALIC=DejaVuSerifCondensed-Italic APPX_PDF_FONT_SERIF_BOLD_ITALIC=DejaVuSerifCondensed-BoldItalic Unicode Fields and CollationUnicode fields are using collation for sorting and comparison instead of ASCII character codes. This causes some behavioral differences between raw fields and Unicode fields in APPX that you should be aware of. Sorting a Unicode field can have a different result from sorting a Raw field. Since APPX uses collation for sorting Unicode fields, depending on the collation used, you may see different sorting results. Here is an example that shows the differences in result of sorting a Unicode field and a raw field with similar values: RAW -------- Unicode  In this case APPX uses the default system collation on a Windows 10 machine which is "en_US".
Queries also use collation to sort Unicode fields. So, sorting a Unicode field and a raw field with similar data may result in different sort order. You can use "APPX_QSORT_COL_NAME" and "APPX_QSORT_COL_STRENGTH" environment variables to change the collation used in query processes to sort Unicode fields. If these environment variables are not specified APPX uses the system's collation which also can be overridden (see below).
Comparing Unicode Alpha fields may surprise you. If you are using Raw alpha field and run a statement like:
In this case APPX uses the default system collation on a Windows 10 machine which is "en_US".
Queries also use collation to sort Unicode fields. So, sorting a Unicode field and a raw field with similar data may result in different sort order. You can use "APPX_QSORT_COL_NAME" and "APPX_QSORT_COL_STRENGTH" environment variables to change the collation used in query processes to sort Unicode fields. If these environment variables are not specified APPX uses the system's collation which also can be overridden (see below).
Comparing Unicode Alpha fields may surprise you. If you are using Raw alpha field and run a statement like: The result will be TRUE since ASCII code for character 'a' is larger than 'A'. However, if you run the same statement on Unicode fields (based on the collation used) the result may be FALSE. In case of "en_US" collation, the result will be FALSE but if you use "en_US_POSIX" collation, the result will be TRUE. You can override the collation APPX uses by setting APPX_UCODE_COL_NAME and APPX_UCODE_COL_STRENGTH environment variables. However, there are some things you need to consider before doing that:
64-bit APPXAPPX 6.1 has been updated to run as a 64-bit application on some platforms. You now have the choice of installing APPX as either a 32-bit or 64-bit application on both Linux and Windows. On other platforms APPX 6.1 remains a 32-bit application. Both versions can be installed and operate on the same server at the same time if they are installed in to separate directories. Regardless of whether you install APPX as 32-bits, 64 bits or both, the applications you develop or upgrade from, will run on either 32 bit or 64-bit 6.1 APPX without further consideration as to bitness.External Databases Quick RestructurePrior to now, when restructured an external database, Appx would build a new table then transfer the data from the old table to the new table, delete the old table then rename the new table to the original table name. This method is inefficient particularly when the table had many records in it. Now, Appx will analyze the changes that are being made and if they met certain criteria (listed below) then Appx will use SQL commands to restructured the external database. Otherwise, if the new restructuring criteria is not met, Appx will behave as it has in the past. New restructuring criteria that will cause Appx to use SQL commands:
Desktop Client Uses external Text ViewerThe Desktop Client now uses an external program for viewing text report. Previously these would be displayed in the client itself. The text viewer to use is specified in the client settings: If no viewer is specified, it will be opened using the desktop default for .txt files.
If you wish to use Appx Report Viewer, you can set "useAppxTxtReportViewer" to true in your client's setting.
If no viewer is specified, it will be opened using the desktop default for .txt files.
If you wish to use Appx Report Viewer, you can set "useAppxTxtReportViewer" to true in your client's setting.
Language TranslationLanguage Translation uses the new .UTIL COMPUTE HASH to compute hash values in the Dictionaries. Your Dictionaries are automatically converted during the migration.New Predefined FieldsAs a convenience, number of new fields have been defined for 6.1.0 as shown below. Work Fields:
New & Revised APIsAll the .TEXT APIs have been reworked to accept Unicode strings up to 1M in length. The .TEXT LOWER TO UPPER and .TEXT UPPER TO LOWER use the Unicode library to convert text. If you have applications that add or subtract 32 from the ASCII value to convert case, be aware that this technique will not work with Unicode data (unless the Unicode field only contains US ASCII characters). The .STREAM functions have been reworked to read or write data in UTF-8 format. The regular expression library has changed to support unicode characters. It also supports more complex patterns. The following APIs were added: .TEXT FROM UNICODE - transcodes a Unicode field to a Raw field, with control over characters that can't be transcoded. .TEXT GET UNINAME - returns the name of the Unicode character. .TEXT SET UNINAME - sets a Unicode character by name. .TEXT TO UNICODE - transcodes a Raw field to a Unicode field. .TEXT UNICODE COMP - compares 2 Unicode fields. .ENV GET ENCODINGS - populates --- ENCODING with all the valid text encodings .UTIL COMPUTE HASH - accepts an extra flag to compute the hash on the Unicode stringAPI HelpIn the ILF editor, when your cursor is on a line with an API statement, if you press help (F1), you will see a brief explanation of that API statement displayed along with some example code that can be cut & paste into your own code. You can also view the wiki page for that function for more detailed explanation by pressing the "View Web Page" button.

New Widget fieldsThere were a number of GUI capabilities that were previously only accessible via macros (@xxx@SLN - Layering @SFP - Focus Painting @SMV - Movable @SLUB, @SSPO @TSRN - Show Row Numbers on Tables (HTML client only) @TSFB - Show footer bar on Tables (HTML client only) @TCSS - Case Sensitive Sorting on Tables (HTML client only) @FULC - Suppress use of Local Connector (HTML client only) The migration utility will convert the macro to the formal specification when it can and the macros still work if you prefer those. Here is a sample GUI Attributes screen showing some of the new fields: 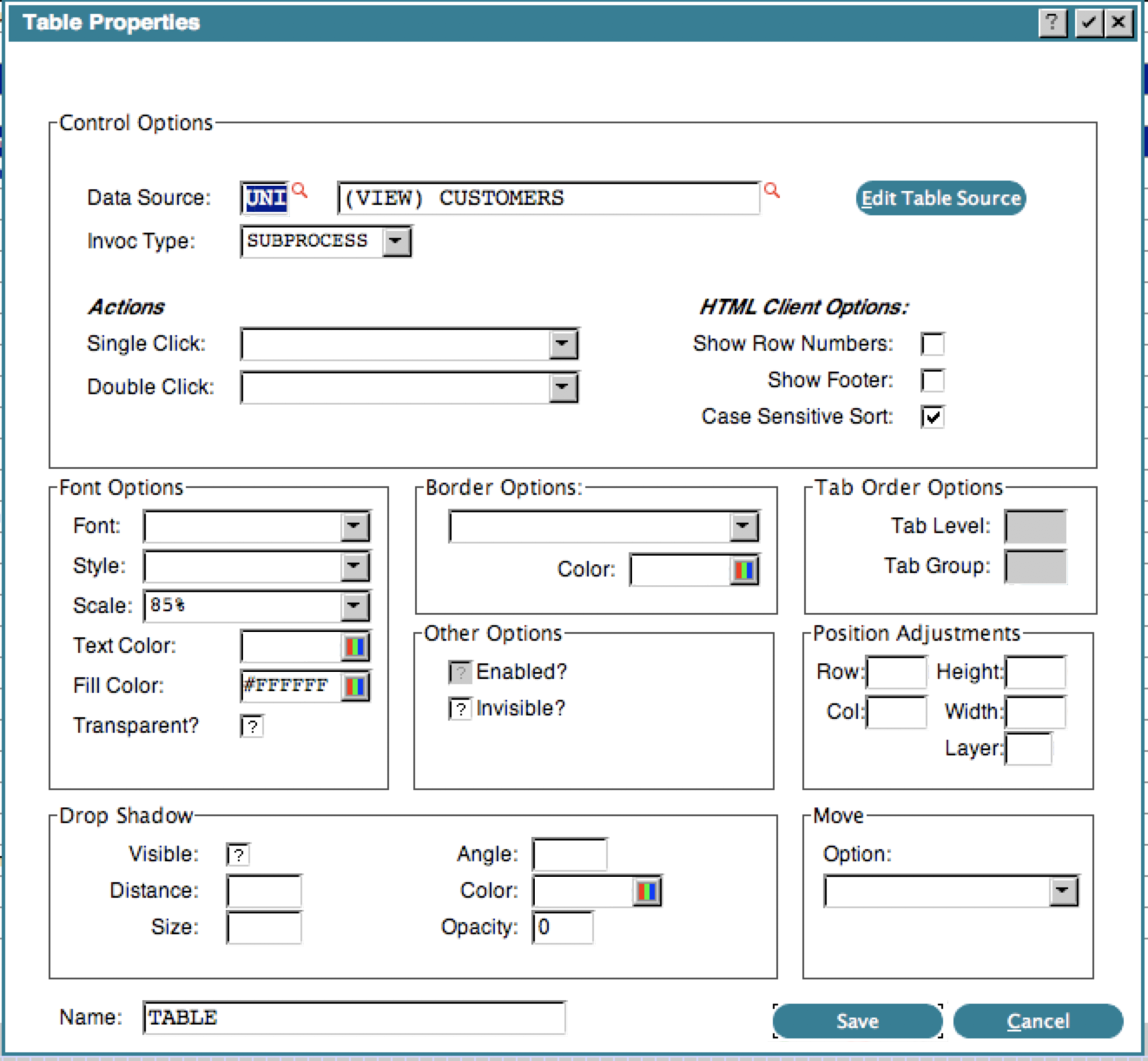 We recommend running with at least 27 rows to accommodate the larger Property screens.
The following fields have been added to --- WIDGET and can be manipulated via ILF:
Drop Shadows
We recommend running with at least 27 rows to accommodate the larger Property screens.
The following fields have been added to --- WIDGET and can be manipulated via ILF:
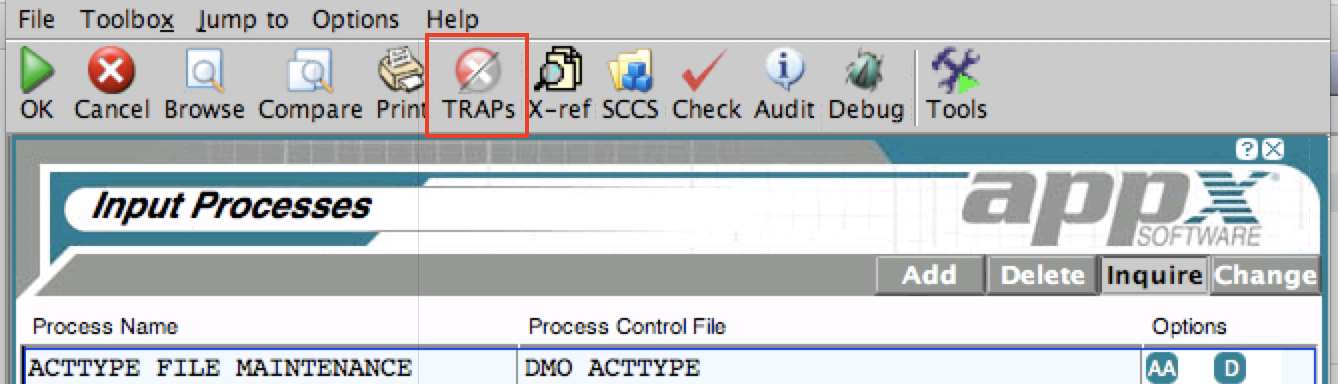
Drop ShadowsWIDGET DS VISIBLE WIDGET DS DISTANCE WIDGET DS ANGLE WIDGET DS OPACITY WIDGET DS SIZE WIDGET COLOR DS (Group Header) WIDGET COLOR DS R WIDGET COLOR DS G WIDGET COLOR DS B WIDGET COLOR DS NL Layering WIDGET LAYER NO Focus Painting WIDGET FOCUS PAINTED Moveable WIDGET MOVE OPTION NO Line Settings WIDGET LINE BASE WIDGET LINE BASE NUM WIDGET LINE STROKE OFF HTML Client Table Settings WIDGET TAB SHOW ROW NO WIDGET TAB SHOW FOOTER WIDGET CASE SENSITIVE HTML Client Local Connector Control WIDGET SUPPRESS LC Consult the online manual at APPX Multi-Release Application Design Manual for details on the Widget specifications, or use the Help key while in Application Design. New TRAP controlYou can now turn TRAPs on or off in an individual process. When you invoke a process, there is a new TRAP Control button: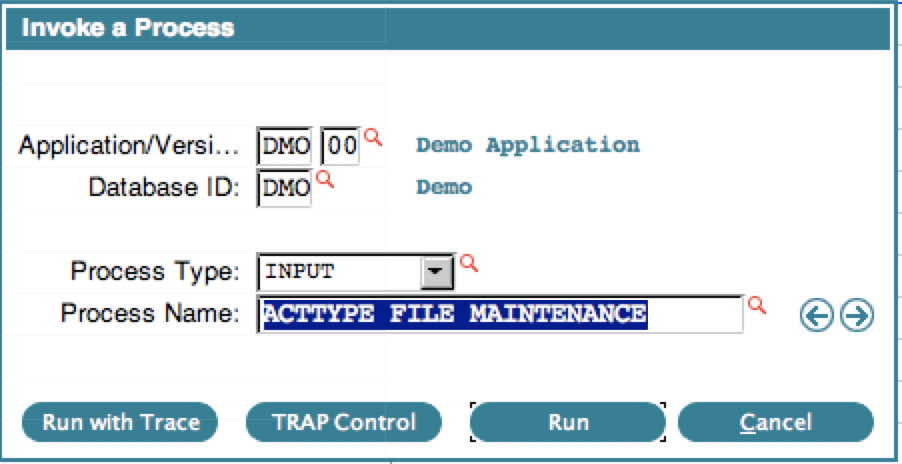 If you click the TRAP Control button, you will get some choices:
If you click the TRAP Control button, you will get some choices:
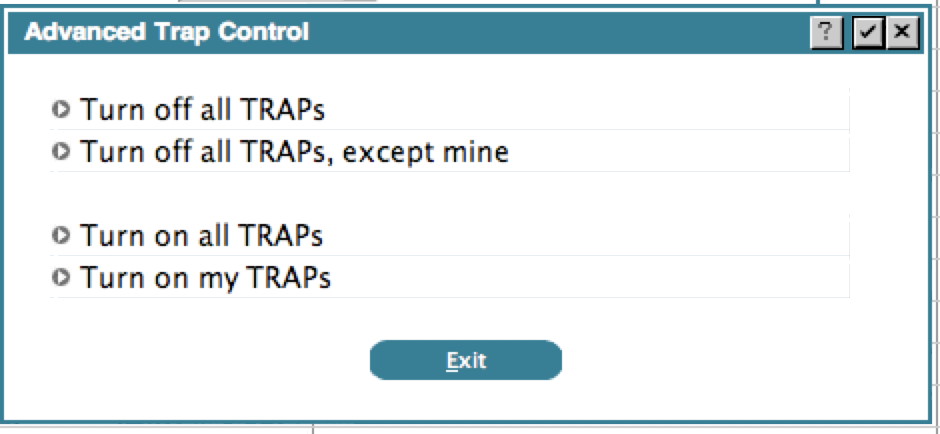 The options are self-explanatory. The system identifies 'your' TRAPs by checking the user id of the user that added the TRAP and the date. Anything you added today will be considered 'your' TRAPs. TRAPs you added in the past, or TRAPs added by other designers are not considered 'your' TRAPs.
This option is also available in the Toolbar and Toolbox pulldown menu while at the Process level:
The options are self-explanatory. The system identifies 'your' TRAPs by checking the user id of the user that added the TRAP and the date. Anything you added today will be considered 'your' TRAPs. TRAPs you added in the past, or TRAPs added by other designers are not considered 'your' TRAPs.
This option is also available in the Toolbar and Toolbox pulldown menu while at the Process level:
New flag to suppress Report Dialog boxA new flag has been added to the System Parameters to allow you to suppress the PDF Confirmation Dialog box: Normally when a report document is produced and the 'Print on Screen' flag is checked the document will be uploaded to the user's desktop. At that point, a Report Confirmation Dialog box will appear and the user can continue to the next job step or choose to cancel the job.
In many cases, this is unnecessary. You can check this box to globally skip this dialog box.
Normally when a report document is produced and the 'Print on Screen' flag is checked the document will be uploaded to the user's desktop. At that point, a Report Confirmation Dialog box will appear and the user can continue to the next job step or choose to cancel the job.
In many cases, this is unnecessary. You can check this box to globally skip this dialog box.
Jump to process from audit historyWhile viewing Audit History in Application Design, you can jump to that process/file/field: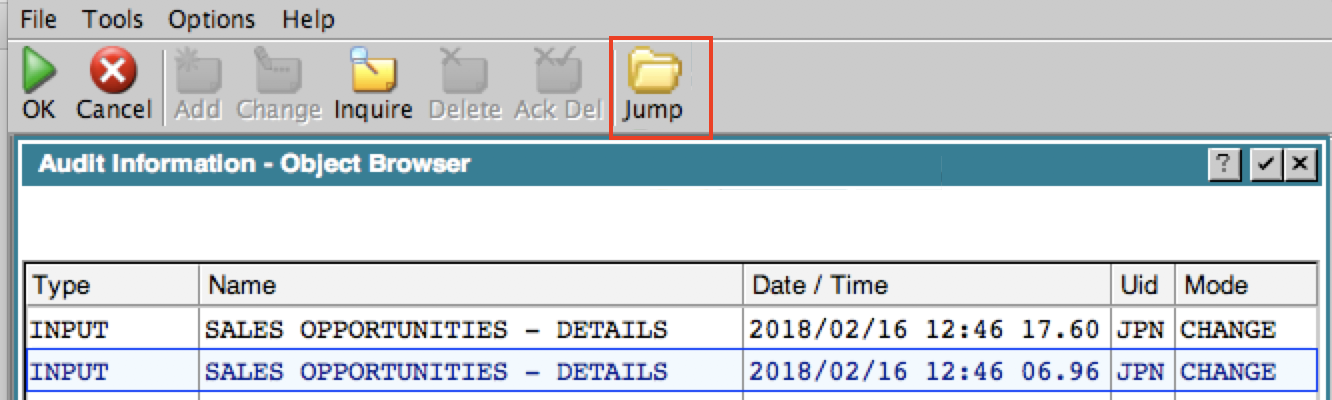 The Audit Browser only shows the process information, but if the change was actually made at the Image level, the Jump button will take you to that Image.
The Audit Browser only shows the process information, but if the change was actually made at the Image level, the Jump button will take you to that Image.
Jump to O/C from Button GAWhile viewing the GUI Attributes of a Button, you can Jump to the Optional Child specified by the button: In this example, clicking the 'Children' button in the Toolbar will take you to Optional Child 1, since the button fires USER 1.
In this example, clicking the 'Children' button in the Toolbar will take you to Optional Child 1, since the button fires USER 1.
New Font - ResourceA new Font Type of 'RESOURCE' is available.: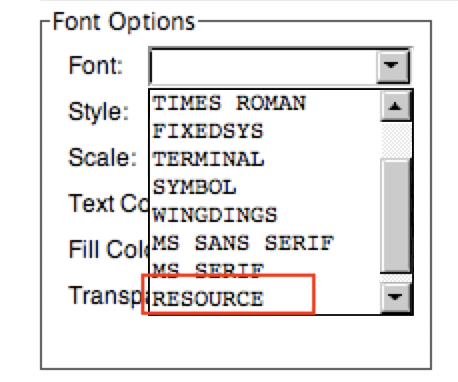 Choosing this font type will cause APPX to use the font specified by the Named Resource. If you choose this font type, you must also enter a Named Resource.
This replaces the technique described where you have to read the WIDGET record and indirectly set WIDGET FONT to 10 via ILF. Now you can simply choose the font RESOURCE.
Choosing this font type will cause APPX to use the font specified by the Named Resource. If you choose this font type, you must also enter a Named Resource.
This replaces the technique described where you have to read the WIDGET record and indirectly set WIDGET FONT to 10 via ILF. Now you can simply choose the font RESOURCE.
New utility to check for duplicate shortcutsA new utility has been added to the 'Tools' tab in Application Design - 'Check for Dup Shortcuts'. It will list all the shortcuts used in the application and flag the ones it thinks might be duplicates: In this example, the letter S is used for both the 'Save' button and the 'Sales Opport.' button and W is used for both 'Weather' and the WWW button.
In this example, the letter S is used for both the 'Save' button and the 'Sales Opport.' button and W is used for both 'Weather' and the WWW button.
0LA Output STANDARD ACTION LOG and 0LA Input CONFIRMATION (END) included in 0LC and can be hookedThe Output STANDARD ACTION LOG and the Input CONFIRMATION (END) have been added to application 0LC and can now be hooked.Bugs Fixed6.1.0:The following bugs were addressed in this Release:
New Features/Enhancements6.1.0:The following features and enhancements were implemented in this Release:
Known Issues
Comments:Read what other users have said about this page or add your own comments.-- BrianRyan - 2021-04-14
| |||||||||||||||||||||||||||
View topic | History: r48 < r47 < r46 < r45 | More topic actions...
Ideas, requests, problems regarding TWiki? Send feedback